Mark Baker has published a new book called Structured Writing: Rhetoric and Process. It is probably the most important book on technical communication since Anne Gentle’s Docs Like Code. In this post, we’ll look at what the book covers. We’ll also include quotations from Mark’s book and his website.
About the book
The book provides an overview of structured writing techniques and systems, the challenges with each of them, and suggests a different approach to structured writing.
What is structured writing?
“Structured Writing is a tool for managing the complexity of your content system and making sure all of that complexity gets handled by people with the right skills and resources. The ultimate objective is to enhance both process and rhetoric.”
“Structured writing is simply the technique you use to partition and transfer complexity around your system so that everyone on the team can do their jobs better.”
The different writing domains
The book begins by explaining the different content domains:
- Media
- Document
- Management
- Subject
Mark uses recipes as an example throughout the book, so let’s continue using that. Imagine you are a writer who has to publish a recipe for flapjacks (the British version) onto a number of different websites:




You can see from the images above, they use different colours, fonts and layouts. They differ in their use (or not) of lists. They have links to different related topics, in different parts of the document.
Writing in the media domain
If the writer is working in the media domain, the presentation and the content are “baked” together in each individual website. The writer has to think about (and create) the typography, design and words. If they want to make a change to the colours, font sizes, layout, links, or words, they have do this in each individual document.
Writing in the document domain
If the writer is working in the document domain, the media domain issues are partitioned and moved outside of the document. For example, they can move the decisions on the colours and font sizes to a cascading stylesheet. They only need to make a change to the stylesheet, rather than each individual web page. Someone, or some thing, can manage that issue for the writer.
Writing in the management domain
If the writer is working in the management domain, the writer can move some (but not all) of the linking and content management activities to a content management system.
However, Mark states they are recording how the content is managed, in with the content. If they want to write content that is specific to a particular type of user or product, they need to create conditional text. For example, they might need to replace an ingredient with an alternative, so that the recipe is suitable for people with specific dietary needs.
Writing in the subject domain
If the writer is working in the subject domain, they only write about the subject matter itself. They can focus on writing the recipe, and defer the decisions on the typography, design and linking. The media, document and management domain elements are recorded and managed for the writer elsewhere.
How we write today
“Most current structured writing systems are either wholly or principally document-domain systems.”
Side note: In fact, primary school children are encouraged initially to write in the media domain. When they are taught how to use Microsoft Word, they are encouraged to use it like a desktop publishing (DTP) application – make the text sparkly, change its colour, make it bigger. They told to create posters and flyers. They are not taught how to use Word’s styles.
Mark states this wasn’t always the case:
“Desktop publishing was revolutionary in its day because it combines three jobs into one, and eliminating communication overhead between writers, designers, and typesetters. This eliminated the communication overhead, but it made the writer’s job more complex.”
Rhetoric
The book looks at rhetoric and the process of writing, the places where rhetorical decisions appear. Rhetoric is essentially the study of what you say, and how you say it. In this book, Mark looked at rhetoric in the sense what you say – the structuring and organising content. He didn’t look at the eloquence of language – how you say it.
Rhetoric is very important in writing. At Cherryleaf, when we improve company policies and procedures, a lot of what we do at is define and create a rhetorical structure. Each procedure states who it affects, what they must do, when they must do it, who is the “owner” of the procedure etc. We have just finished a writing project for an API documentation portal. We documented seven APIs, and made sure the documentation for each API had the same topics, in the same order. Again, we created a rhetorical structure.
Why adopt a subject domain approach to writing?
The core message of the book is that writers should be writing in the subject domain.
“Why should the author have to deal with things like conrefs and maprefs, which have nothing to do with the subject they are writing about?”
Essentially, you are writing content like it is data. The basic message is you can:
- Use software (algorithms) to process the content
- filter content
- re-present it
- Reduce the complexity for the writer, so they can focus on writing.
The book looks at the benefits of writing in the subject domain in depth. There are probably over 100 pages on how it affects: content management, collaborative writing, avoiding duplication, presenting tables, metadata, terminology, reuse, computer generated content, merging and extracting content, linking, filtering content, and more.
Structured writing languages
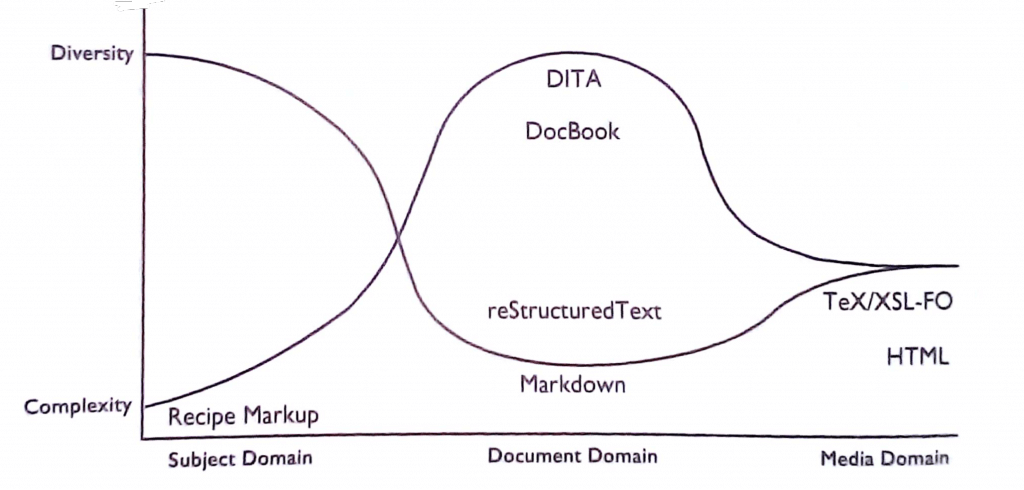
The book looks at pros and cons of different structured writing languages such as DITA, DocBook, Markdown, ReST and AsciiDoc.
“The vast majority of structured writing today is done in XML using a structured XML editor which presents a pseudo-WYSIWYG graphical editing environment to the writer. This is inherently a document-domain writing environment. It has many problems even for working in the document domain, but it is even more difficult to work in when writing in the subject domain.
Many people today prefer to work in lightweight markup languages such as MarkDown which you can create easily using a simple text editor. However, all current lightweight markup languages are simple document domain languages.”
The differences are shown in this diagram:
SAM
In the book, mark proposes a new markup a language, to make writing in the subject domain easy for writers. SAM (Semantic Authoring Markup) is an extensible markup language with syntax similar to Markdown but semantic capability similar to XML.
“SAM is designed to make the structure of structured documents clear and explicit to the writer, while also making them simple and straightforward to type.”
“SAM is not intended to completely replace XML, which is more general than SAM and works fine for most of the things it is used for. SAM is intended as a front-end authoring language for structured writing systems that would still use XML internally.”
So what does SAM look like? It looks like this:
recipe: Feelgood flapjacks
introduction:
These healthier oat bars use bananas and apple to bind the mixture, so you can cut down on the fat and sugar.
This is a classic {British} (country) recipe.
ingredients:: ingredient, quantity, type, alternative
butter, 50g
peanut butter, 2 tbsp, smooth
honey, 3 tbsp, runny, maple syrup
bananas, 2, ripe and mashed
apple, 1, peeled and grated
rolled oats, 250g
dried apricot, 85g, chopped
raisin, 100g
mixed seed, 85g
preparation:
1. Heat oven to 160C/140C fan/gas mark 3.
2. Grease and line a 20cm square tin with baking parchment.
3. Heat the butter, peanut butter and honey or maple syrup in a small pan until melted.
4. Add the mashed banana, apple and 100ml hot water, and mix to combine.
5. Tip the oats, the dried fruit and the seeds into a large bowl.
6. Pour in the combined banana and apple and stir until everything is coated by the wet mixture.
7. Tip into the cake tin and level the surface.
8. Bake for 55 mins until golden.
9. Leave to cool in the tin.
10. Cut into 12 pieces to serve or store in an airtight container in the fridge.
prep-time: 10 minutes
serves: 12
nutrition:
serving: 1 flapjack
calories: 218 kcal
total-fat: 8 g
saturated-fat: 3 g
salt: 1 mg
protein: 6 g
total-carbohydrate: 29 g
dietary-fiber: 4 g
sugar: 17 g
protein: 6 g
All the media, document and management domain information is stored outside of this document.
This means we could use an algorithm to:
- Change “fibre” to “fiber”, depending on the reader’s location.
- Include it in a book of British recipes.
- Include it in a book for meals with fewer than 10 grams of fat.
- Change grams to the imperial measures used in the USA (which we believe are knuts, sickles and galleons), for the US market.
Managing documentation
The book also looks at the problems with using a “block and map” approach to documentation (like you have with DITA) and a conditional text approach (like you have with Flare and RoboHelp).
Mark proposes an alternative, bottom-up information architecture, which he calls SPFE. SPFE works by automatic collection and linking of content based on metadata, rather than using a top down approach of using tables of content or DITA maps.
Structured writing and “Every Page is Page One”
He connects SAM and SPFE to the “Every Page is Page One” (EPPO) philosophy that Mark popularised a few years ago.
EPPO is an approach to information design which Mark calls “bottom-up information architecture”. It is based on the users finding content mainly by search engines. This can throw the reader into any page in a content set (which means every page is page one in the reader’s journey). It can be their final destination, or it can direct them (via hyperlinks) on to other topics they may need. Wikipedia is the classic example of a bottom-up information architecture.
However, sites like Wikipedia require a lot of effort to create and manage the links. The book argues that to do “Every Page is Page One” efficiently, you need to adopt SAM and SPFE.
Criticisms
We liked this book. But…
- If you like the approach put forward in the book, and you want to adopt them, you’re likely to hit a snag. SAM is a work in progress. To convert your subject domain content into content for users, you’ll need to be comfortable using scripts from a command line interface.
- This approach reminded us of the Headless CMS systems that are emerging, where content is stored as data (in this case as JSON objects). At this stage, Gatsby with Strapi, or Sanity seem more likely to be adopted than SAM. (We’ll be looking at Headless CMSs and Sanity in an upcoming episode of the Cherryleaf podcast).
- It’s not clear if SAM supports auto generated numbered lists.
- There’s no conclusion at the end of the book 🙁
Summary
This is a useful book if you want to understand why your implementation of DITA isn’t working, and what alternative approaches are available. Equally, if you want a better alternative to Word or a Help Authoring Tool.
We’ll finish with the last paragraph from the book:
“Getting there may require your team to learn new skills, or it may require you to bring in staff with the needed skills. Don’t regard bringing in those skills as a downside of structured writing. Instead, look at it as a method to better handle the complexity of content creation.”
What do you think?
Share your thoughts in the comments section below
Every first instance of an initialism should be explained. You’ve not explained what SPFE stands for, which is interesting considering it’s arguably one of the author’s primary proposals.
The name SPFE is an acronym for the four layers of the SPFE architecture: Synthesis, Presentation, Formatting, and Encoding. https://spfe.info/
Asciidoc is essentially a lightweight DocBook, and has a lot more in common with its XML parentage than with Markdown. The most customizable PDF toolchains for Asciidoc, to use one example, are (or have been, for a long time) DocBook-based, which illustrates this transparency. The Asciidoc WG also considers DocBook round tripping to be a core function of the language.